缓存一致性与内存一致性
缓存一致性和内存一致性是多处理器系统中的两个不同概念,它们解决的是不同类型的内存访问问题。
缓存一致性协议(如 MESI 协议)用于解决多个处理器对相同内存位置进行访问和修改时的数据一致性问题。它确保各处理器的缓存中针对同一内存地址的副本保持一致,避免因缓存不同步而导致的数据错误。
而内存一致性关注的是处理器对多个不同内存地址的访问顺序问题。当不同处理器的内存访问顺序与程序代码中的预期顺序不一致时,就会引发内存一致性问题。它要求各处理器按照一定的规则访问内存,以保持程序逻辑的正确性。
简而言之,缓存一致性解决的是同一内存位置的数据同步问题,而内存一致性则涉及多个内存位置的访问顺序问题。
内存乱序访问产生的原因
内存乱序访问的原因可以从两个方面来理解:程序顺序(Program Order, PO)和内存顺序(Memory Order, MO)。程序顺序是指程序代码中编写的内存访问序列,反映了程序员预期的指令执行顺序。按照程序顺序,指令应该依次被执行,以确保程序的逻辑正确性。然而,在实际执行中,系统中可能存在一种不同的顺序,即内存顺序。
内存顺序是指系统中所有处理器对内存操作达成一致的访问顺序。由于现代计算机系统通常由多个处理器共同操作共享内存,为了提高整体性能,这些处理器可能会对内存操作进行重排序,从而产生与程序顺序不一致的内存顺序。
这种内存乱序访问的现象主要是为了优化程序执行效率,通常发生在两个阶段:编译阶段和执行阶段。在编译阶段,编译器会对代码进行优化,这可能会导致指令的重排序,以提高执行效率。在执行阶段,多个 CPU 之间的交互也会引起内存访问顺序的不一致。
在单处理器系统中,CPU 对指令的乱序执行和重排对于程序员来说是透明的,即程序的执行结果与顺序执行的结果是一致的。然而,在多处理器系统中,不同的处理器(或称为观察者)可能会观察到不同的内存执行顺序,这与指令的实际执行顺序不完全一致,从而导致潜在的同步问题和数据不一致性。
几种常见的一致性模型
在多处理器系统中,内存一致性模型决定了不同处理器之间如何观察和执行内存操作的顺序。以下介绍几种常见的一致性模型:
顺序一致性模型(Sequential Consistency, SC)
顺序一致性模型的概念最早由 Leslie Lamport 在 1979 年的论文《如何构建正确执行多处理程序的多处理计算机》中提出。按照他的定义:
任何执行的结果都与所有处理器的操作按照某种顺序依次执行的结果相同,并且每个处理器的操作在这个顺序中出现的顺序与其程序中指定的顺序一致。满足这一条件的多处理器被称为顺序一致性系统。
顺序一致性模型保证了每个加载(Load)和存储(Store)指令按照程序中指定的严格顺序执行,确保了“读->读”、“读->写”、“写->写”以及“写->读”四种操作的顺序。这种模型提供了最强的内存一致性保证,但代价是较低的执行效率,因为它不允许任何形式的指令重排序。
处理器一致性模型(Processor Consistency, PC)
处理器一致性模型是顺序一致性模型的弱化版本,它放宽了对“写->读”操作顺序的要求。该模型允许处理器在读取时从存储缓冲区(Store Buffer)中获取一个尚未写入缓存的值,即使这个值还没有被其他处理器看到。x86-64 实现的全序写(Total Store Ordering, TSO)模型就是处理器一致性的一种。TSO 允许一定程度的乱序执行,提高了系统的性能,同时仍然提供了较强的一致性保证。
弱一致性模型(Weak Consistency, WC)
弱一致性模型进一步弱化了处理器一致性模型的要求,放宽了对“读->读”、“读->写”、“写->写”以及“写->读”四种操作顺序的约束。为了确保程序执行的正确性,程序员需要在合适的地方显式添加同步操作。在这种模型中,多处理器系统的内存访问满足以下三个条件时称为弱一致性内存访问:
- 对全局同步变量的访问是顺序一致的
- 在一个同步操作(如内存屏障指令)执行之前,所有先前的数据访问必须完成;
- 在一个正常的数据访问(如数据访问指令)执行之前,所有先前的同步操作(如内存屏障指令)必须完成。
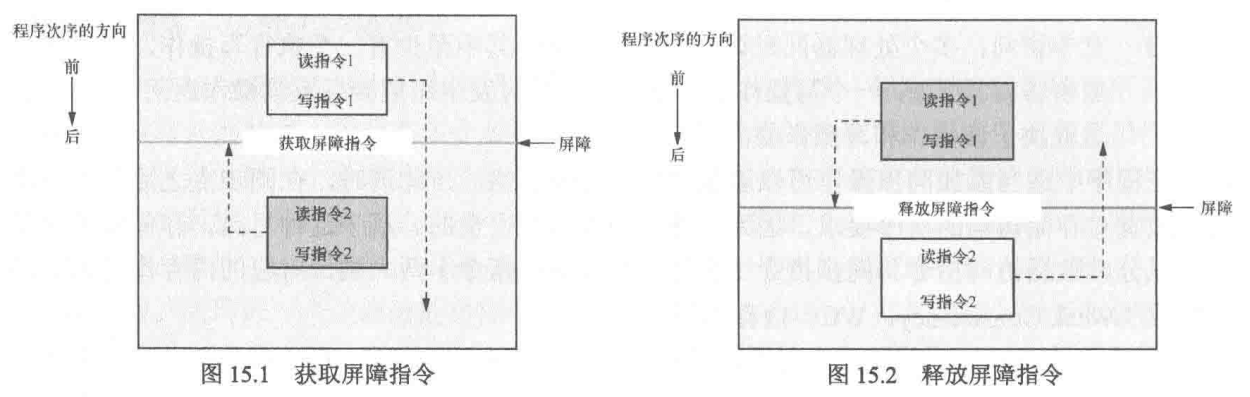
释放一致性模型(Release Consistency, RC)
释放一致性模型是在弱一致性模型的基础上引入了“获取”(acquire)和“释放”(release)屏障原语,用于简化共享数据的互斥访问。
在该模型中,“获取”屏障原语后面的读写操作不能被重排到该屏障之前,“释放”屏障原语前面的读写操作不能被重排到该屏障之后。这种机制能够更高效地管理多处理器系统中的共享数据访问,提高并行性能。
这些内存一致性模型提供了从严格到宽松的不同选择,适应不同的应用需求和性能要求。选择合适的一致性模型对多处理器系统的设计和优化至关重要。
四种内存乱序
在多处理器系统中,为了优化性能,处理器可能会对内存操作进行不同类型的乱序执行。这种乱序行为包括四种主要类型,每一种都会以不同的方式影响多线程程序的正确性和一致性。
LoadLoad 乱序
LoadLoad 乱序指的是后续的加载(读取)操作可以在先前的加载操作完成之前开始,或者两个加载操作的完成顺序与它们的发起顺序不同。这意味着处理器可能会优先执行后发起的加载操作。这种乱序优化可能有助于提高程序的执行速度,但如果未加以控制,可能会导致某些线程读取到不一致的数据。
LoadStore 乱序
LoadStore 乱序表示一个存储(写入)操作可以在之前发起的加载操作完成之前开始执行,或者写操作可能“超越”读操作。尽管这种优化可以提高处理器的性能,但在多线程程序中可能导致意外的行为。例如,一个线程可能会看到数据被写入之前的状态,导致逻辑错误或数据不一致。
StoreLoad 乱序
StoreLoad 乱序是四种乱序类型中对编程模型影响最大的一种。它允许一个加载操作在之前的存储操作完成之前开始,或者读取操作可能看到写操作的结果,即使这个写操作在程序中的顺序上应该发生在读操作之后。这种乱序执行可能导致一个线程读取到另一个线程的“旧”值,而不是最新写入的值,从而引发数据同步问题。
StoreStore 乱序
StoreStore 乱序涉及两个连续的存储操作,其中后一个存储操作可以在第一个操作完成之前开始,或者它们的完成顺序与它们被发起的顺序不同。这意味着,后一个写操作的结果可能在前一个写操作的结果对其他处理器可见之前就已经被观察到,从而造成数据顺序的不一致。
管理内存乱序的重要性
正确管理这些乱序行为对于并发编程至关重要,特别是在设计无锁数据结构和编写多线程程序时。如果不加以控制,这些乱序可能导致数据不一致、难以重现的错误和程序崩溃。为了避免这些问题,现代处理器和编程语言提供了各种内存屏障(Memory Barriers)或内存顺序(Memory Order)指令,确保在关键的程序点上强制执行所需的内存操作顺序。这些机制帮助程序员在优化性能的同时,维护数据的一致性和正确性。
使用Litmus工具分析内存乱序 - 以x86-TSO为例
在并发编程中,理解和验证内存模型的行为对于确保程序的正确性至关重要。以 x86 Total Store Order (x86-TSO) 为例,我们可以使用 Litmus 测试工具来分析内存乱序现象,并了解如何通过内存屏障来避免这种情况。
Litmus工具可以在这里在线试用,也可以安装到本地环境
x86 Total Store Order (x86-TSO)
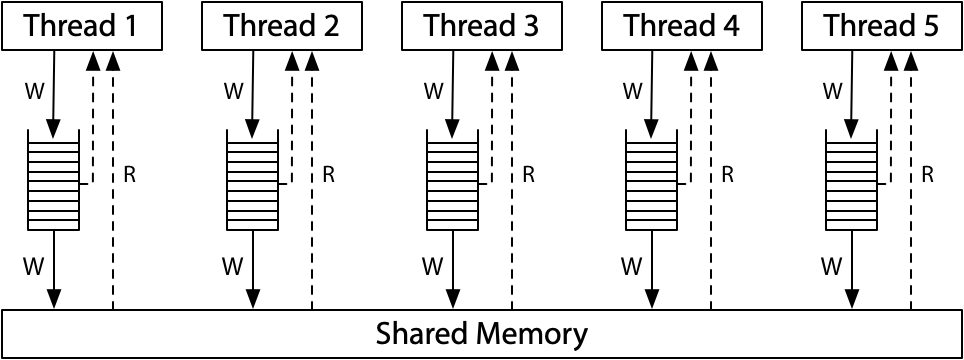
在 x86 架构中,Store Buffer(存储缓冲区)用于暂时存放处理器的写操作,而不立即将其写入主存。这种机制提高了处理器的性能,因为它允许处理器在写操作尚未完成时继续执行后续指令。然而,Store Buffer 也导致了某些内存操作的可见性问题,特别是在多处理器环境中。
x86 Total Store Order (x86-TSO) 模型的特性正是由这种 Store Buffer 机制决定的。由于写操作在 Store Buffer 中暂存,x86-TSO 模型保证了一些关键特性,同时也做出了一些基于性能的妥协:
- 写操作顺序一致性:所有写操作按照程序的顺序执行,并对所有处理器可见,即写操作在 Store Buffer 刷新到主存之前,不会被其他处理器看到。
- 读操作的自我可见性:处理器可以立即看到自己在 Store Buffer 中的最新写入,即本处理器的读操作可以从 Store Buffer 中读取未提交到主存的值。
- 防止某些重排序:为了避免因 Store Buffer 导致的读写乱序,x86-TSO 禁止写操作与其后的读操作重排序,确保读写顺序一致。
- 允许部分读操作重排序:为了进一步提升性能,处理器允许一些读操作的重排序,但仍然遵循严格的规则以保证程序的正确性。
使用 Litmus 验证 x86 的 StoreLoad 乱序
我们可以使用 Litmus 工具来验证在 x86-TSO 内存模型下的 StoreLoad 乱序行为。以下是一个示例代码:
X86 SB
{ x = 0; y = 0; }
P0 | P1 ;
MOV [y],$1 | MOV [x],$1 ;
MOV EAX,[x] | MOV EAX,[y] ;
exists
(0:EAX=0 /\ 1:EAX=0)
在执行该代码后,Litmus 会生成四种可能的结果,分别对应不同的执行顺序。
结果1
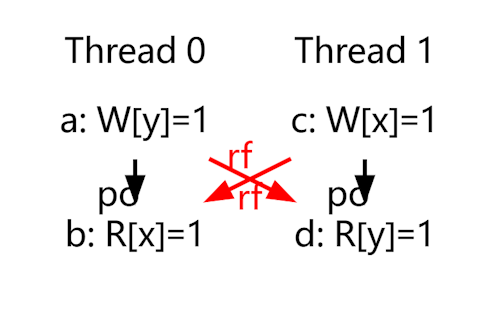
在结果1中,程序按照严格的顺序执行,每个处理器的内存操作顺序与程序中的顺序一致。
图中,po(Program Order)表示程序顺序,rf(Reads-From)表示每个读操作从哪个写操作中读取的值。由于内存操作按照预期顺序执行,这种情况没有进一步的乱序行为,因此不需要进一步分析
结果2/结果3

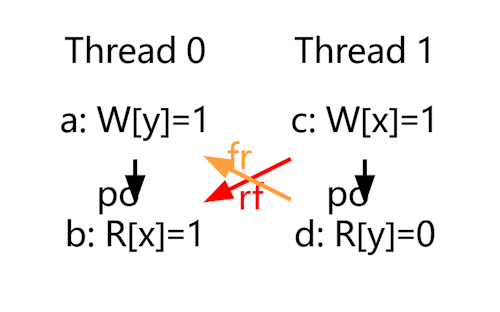
结果2和结果3是对称的,表示在执行过程中,内存的读取发生了“乱序”,即读取操作被重排到了写入操作之前。在 Litmus 中,这种情况被标记为 fr(From-Read),表示一个写操作覆盖了一个读操作所读取的值,即这个写操作发生在读操作之后。这种“写读”操作的乱序可能是由于执行顺序的不同,也可能是内存模型的顺序造成的。
结果4
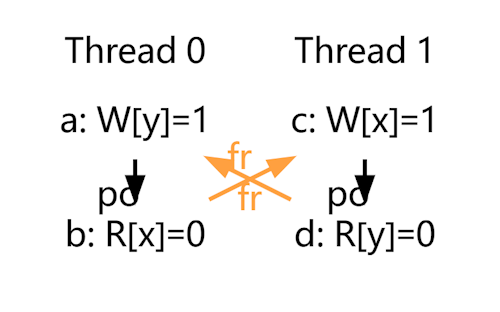
结果4表示两个线程各自都发生了 fr,即每个线程的读操作都被重排到了写操作之前。这种情况展示了最复杂的乱序行为,其中两个线程的读操作分别“超越”了各自的写操作。
使用内存屏障(MFENCE)指令避免内存乱序
为了避免这种乱序情况,可以使用 MFENCE(Memory Fence) 指令。在 x86 架构中,MFENCE 是一种强制内存屏障,确保所有在 MFENCE 之前的内存操作(无论是读还是写)在所有 MFENCE 之后的内存操作之前完成。这意味着在同一线程内,MFENCE 保证了内存操作的顺序性:MFENCE 之前的操作对其他线程可见后,才可以执行 MFENCE 之后的操作。
我们可以将 Litmus 代码修改如下,以插入 MFENCE 指令:
X86 SB
{ x = 0; y = 0; }
P0 | P1 ;
MOV [y],$1 | MOV [x],$1 ;
MFENCE | MFENCE ;
MOV EAX,[x] | MOV EAX,[y] ;
exists
(0:EAX=0 /\ 1:EAX=0)
在加入内存屏障后,我们看到结果1到结果3依然会出现,但结果4因 MFENCE 的存在而被避免。通过 MFENCE 确保了内存操作的顺序性,从而防止了某些类型的内存乱序,保证了多线程程序的正确性和一致性。
接下来…
下一篇文章中,我们会介绍C++的内存顺序模型,并且分析更复杂的内存乱序问题
References
- 硬件内存模型
- RISC-V体系结构编程与实践
- How to Make a Multiprocessor Computer That Correctly Executes Multiprocess Programs
- Memory access buffering in multiprocessors
- Litmus: Running Tests Against Hardware
- Herd7 Simulator
- Memory Model Simulation Tool - Herd7
- A working example of how to use the herd7 Memory Model Tool
Comments
comments powered by Disqus