什么是Ceph
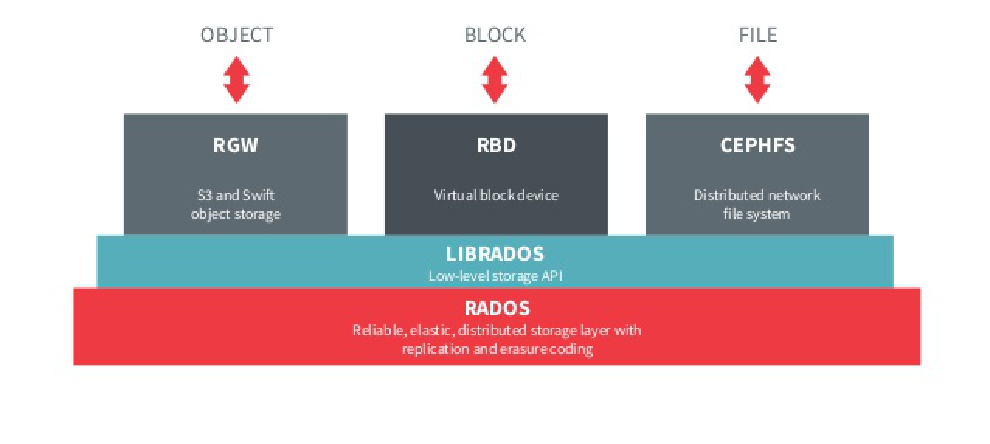
Ceph是一个可扩展的,高性能的分布式存储系统。提供了三种不同类型的接口以适应不同的应用场景:
- block-based: 块存储,可以用做VM的虚拟磁盘
- object-based: 对象存储,与Amazon S3等常用对象存储兼容
- file system: POSIX兼容的分布式文件系统,可以被本地系统挂载,并且能被多个客户端共享
Ceph的特性
由于采用了CRUSH算法,Ceph有着优异的可扩展性(宣称可以无限扩展)。并且借助可扩展性,进而实现高性能、高可靠性和高可用性。
Ceph是一个去中心化的存储系统,无需中心节点进行资源的管理与调度,全部的管理功能由存储节点自治完成。使得整个系统可以自我管理与自我恢复,减少运维成本与管理成本。
RADOS - Ceph的存储引擎
RADOS=Reliable Autonomic Distributed Object Store。RADOS是Ceph底层的存储引擎,所有的接口都建立在RADOS的功能之上。
RADOS中的存储结构
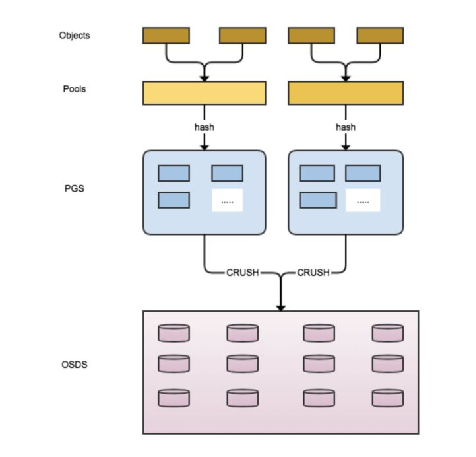
- 存储池(pool):逻辑层,每一个pool里都包含一些放置组
- 放置组(placement-group, PG):逻辑层,一份数据会在PG当中进行灾备复制。每一个PG都对应着一系列的存储节点
- 存储节点(OSD):用以存储数据的物理节点。与PG之间形成多对多的关系。
一份数据在写入RADOS时,会先选中一个pool。Pool中再使用一定的hash规则,伪随机的选中某一个PG。PG会将数据写入多个OSD中。读取数据时,也是类似的规则。
Pool是用户可见的管理数据的基本单位,用户可以对Pool进行一系列的配置(权限控制、使用SSD or HDD、使用数据拷贝 or 纠删码,etc.)。而PG与OSD对于用户是不可见的。

PG的组织
在一致性哈希中,我们使用节点来划分哈希值域。这种方法的问题是,如果产生了数据不平衡,我们需要重新进行划分值域来进行再平衡。这会造成大量的数据迁移。
CRUSH采用了虚拟节点(也就是PG)将哈希值域划分成了固定的等长区域。这种方法在单条数据与物理节点之间加入了一个虚拟层。之后,再使用哈希取模的算法确定数据属于哪个PG。使得数据的迁移是以虚拟节点为单位,而不是对每一条数据都重新计算。Ceph官方的建议是,每1个OSD对应着100个PG。
一般情况下,在规划的初期需要确定PG的数目,如果后期需要调整PG,有可能会导致大量的数据迁移,甚至需要服务暂时停止服务。
监控子集群(MON)与Cluster Map

RADOS集群中除了OSD存储节点之外,还有监控子集群(MON),用于存储系统的拓扑结构——Cluster Map。
元数组管理(MDS)节点用于管理CephFS中的文件元信息,后文会有介绍。
不同于传统的中心化管理节点,MON并不会对资源进行调配与调度,而仅仅是一个观测者,用以存储系统当前的拓扑与状态。
MON与OSD、OSD与OSD之间会定时发送心跳包,检测OSD是否健康。如果某个节点失效,MON会更新内部存储的拓扑结构信息(ClusterMap),并且通过P2P协议广播出去,从而使得整个系统都有着(最终)一致的拓扑信息。
主从同步与节点自治
在一个PG中,会有一个主节点(Primary)和一个或多个从节点(Secondary)。主节点负责维护从节点的状态,包括数据复制(replication)、失效检测(failure detection)和失效恢复(failure recovery)。
CRUSH - Ceph皇冠上的明珠
CRUSH是一个可扩展的,伪随机的数据放置算法。以去中心化方法,将PG按规则映射到相应的存储设备上。并且系统的拓扑结构发生变化时,尽可能的减少数据的迁移。
CRUSH的优势
CRUSH对于每一个数据元素使用一个伪随机算法,决定其放置的位置。所以,只要所有参与者都拥有相同的系统拓扑结构信息,那么数据的位置就是一定的。所以我们可以去掉中心节点,采用P2P的方法来进行数据的存储与检索。
并且,由于伪随机算法只与单个PG相关,如果我们操作得当,节点数量的变化并不会引起大量的数据迁移,而是会接近理论最优值。
数据放置(Data Placement)
CRUSH的数据放置算法有很多不同的实现,这里只介绍最常用的straw算法。
Ceph中,每一个OSD节点都有一个权值w,代表着某个节点能支持多少数据的存储与检索。一般来说,权值与节点的容量成正比。
假设一个pool里面有n个PG,在一条新的数据写入时,我们分别会计算这n个PG的length值。
\(f(w_{i})\)是一个只于当前OSD节点权值有关的函数。\(hash(x)\)代表当前PG的哈希值。所以,PG会放置在哪个OSD上,仅与其权值相关。
假设某个OSD节点发生变化时(新加、删除、权值变化),在此受影响节点的数据会迁移到其它的OSD节点。其它OSD节点的原有数据并不会受到影响。
Ceph当中的straw算法有
straw1和straw2。straw1的实现采用了有缺陷f(w)函数,会导致意外的数据迁移。straw2解决了这个问题。
详情请戳这里
主从架构
每个PG所包含的OSD都由CRUSH算法计算得出,并根据配置选出前r个OSD进行主从配对。列表中的第1个OSD做为主节点(Primary),其它的节点为从节点(Secondary)。
主从节点的分配与管理由PG内部进行自治,不需要额外的外部系统进行管理。
CephFS
CephFS是一个POSIX兼容的(共享)文件系统。CephFS利用文件元数据子系统(MDS)来维护目录树结构和文件和目录的元信息(owner, timestamps, inodes, etc.)等。
MDS子系统会在内存里面维护一份Cache,对于需要持久化的信息,会使用WAL的方式写入RADOS里一个专用的Pool当中。
动态树划分(Dynamic Tree Partitioning,DTP)
CephFS的扩展性的关键之一,在于元信息子系统的扩展性。CephFS实现了动态树划分的算法,将目录树结构根据当前系统的负载,将其划分到不同的MDS节点上去。
维护目录树结构的优势在于利用了文件系统的局部性(locality),可以方便的进行预取(prefetch)。动态的树划分,可以保证元信息可以线性增长,以保持高可扩展性。

写在最后
本文基于Ceph的三篇论文综合而成(CephFS、RADOS、CRUSH)。其中加入了一些自己的看法,使其逻辑通顺,并不保证与论文的思路完全一致。
这三篇论文并没有明确的依赖关系,换句话说,需要综合阅读,才能有比较明确的理解。
建议在通读论文后,去学习一下这个视频,会对理解Ceph有很大的帮助。Youtube上面还有很多Ceph的tech talk,可以一并的了解一下。
Ceph相关的书籍以实践居多,只推荐Learning Ceph。
Comments
comments powered by Disqus