背景
基于LSM-Tree的存储引擎
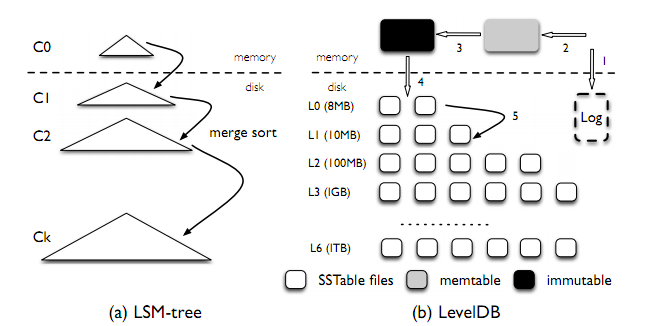
Log-Structed Merge-Tree (a.k.a. LSM-Tree)是当下常用的一种基于磁盘的存储引擎。与Hash索引和B-Tree同为数据库核心的数据结构。
LSM-Tree的优势在于:
- 无需将所有的Key索引在内存中。可以通过分级查找的方式,查询到特定KV在磁盘中的偏移量
- 数据写入与合并使用顺序追加写,最大程度的利用磁盘的顺序写性能
- 对于数据写入,会使用batch方式写入磁盘
- 支持范围查询
LSM-Tree的劣势在于:
- 读放大与写放大
- 无法对单条数据加锁(事务支持)
现在常用的LevelDB和RocksDB,都是基于LSM-Tree的存储引擎。
WiscKey主要解决的问题
LSM-Tree在性能上面的瓶颈主要在于读写的放大。简单说来,假设你的磁盘最大带宽为4GB/s,读写放大倍数为10,那么在应用层的有效吞吐量(Goodput)最多只能达到400MB/s。并且,对于一些大数据集,读写放大的值有可能会非常大(大于100)。
那么是什么原因导致的读写放大呢?我们下面分开讨论。
读放大
我们重温一下LSM-Tree的查询机制:
- 首先在mutable memtable中进行查找
- 然后在immutable memtable中进行查找
- 最后在不同的LSM-Tree层级中的SST file中进行查找
对于1和2,都是内存操作,其耗时与读取磁盘相比可以忽略不计。
对于3,SST file文件的查找会先使用二分查找定位特定KV位于该层的哪一个SST文件中。
如果特定的KV不存在于此SST文件中,会被常驻内存的bloom filter过滤掉,不会真正的读取文件。(大概率,bloom filter的原理了解一下)
如果特定的KV在此SST文件中,会通过index block进行二分查找,确定KV位于哪个block。然后这个block会被从磁盘上读取到内存进行解压,最后通过二分+遍历找到对应的KV。
论文里对于读放大的计算方法有点夸大了。对于RocksDB来说,一般情况下index block和bloom filter都是常驻内存的。除非是内存非常紧张的场景,否则并不会产生论文中如此夸张的磁盘读放大的。
所以读放大主要因为读取一个KV,需要读取+解压整个block。当KV大小远小于block size的时候,问题会更加严重。
写放大
我们再重温一个LSM-Tree的写入机制:
1. 首先写入mutable memtable
2. mutable memtable后续会被sealed,成为immutable memtable
3. immutable memtable会被flush到磁盘,成为L0
4. L0中的数据会在后台,逐层向下合并,直到合并到最底层
层次数据逐层向下合并的过程中,必然会产生写放大。(具体原理这里不展开了)
写放大值可以使用以下方法估算。已知options.max_bytes_for_level_multiplier代表每一层大小的倍数k,并且假设L0与L1的大小相等,总共有N层。那么写放大约为(N - 1) * k + 1。
正文
入活了入活了!
WiscKey的设计目标
- 降低写放大
- 降低读放大
- 对SSD进行优化
- 提供LSM-Tree兼容的API
- 针对现实场景的KV size
WiscKey的设计思路——KV分离
在一般的场景中,在一对KV中,Key的大小远比Value的要小。如果我们在LSM-Tree中只保留Key,那么对于一次读写,我们所要处理的数据就会少很多,从而降低了读写放大。
对于Value,我们会将其存储在另外一个数据结构vLog中。每一次查询,会在LSM-Tree中记录其在vLog中的<offset, length> 。这样一来,读取Value的操作也只有一次磁盘访问,并且不会产生写放大。
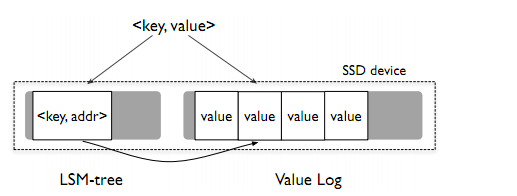
这里有一个疑问,如果按论文里面的设计,vLog里面的数据是不会打包的block进行压缩的,必然会损失capacity。如果打包压缩了,那么读放大并没有显著优化。又如果value size ≈ block size,那么其实在读放大上面的优化也就比较微弱了。
WiscKey的设计挑战
并发范围查找
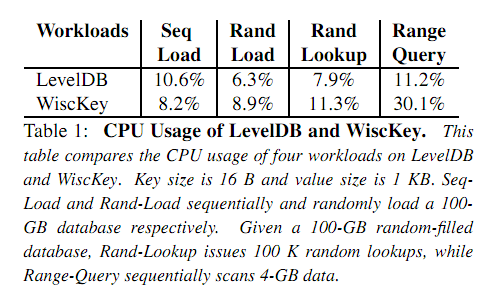
因为使用了KV分离的存储方式,所以范围查找(range query)对于value就会退化成很多次随机读取。
但是由于SSD的并发读取特性,WiscKey会将所需要读取的value的<offset, length>放到一个队列中,多线程并发读取所需要的value。

如图所示,对于较大的value size,顺序读与并发读的throughput基本保持一致。
但是多线程并发读会消耗更多的CPU。
不过对于一个存储系统来说,CPU大概是最不重要的资源了吧(见仁见智咯)
垃圾回收
对于重复写入的KV,LSM-Tree会通过层次合并来将旧值换出。而WiscKey会使用垃圾回收机制来将旧值换出。
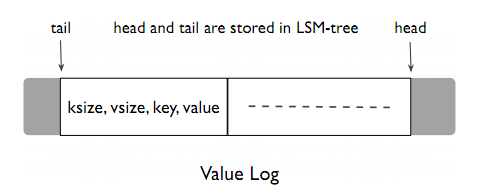
vLog可以视作一个循环数组,head指针表示数据的开头(较新的数据),tail指针表示数据的结尾(较旧的数据)。在head和tail指针之外的空间都视作free space。
当空闲数据小于一定阈值之后,会触发GC。WiscKey会从tail依次读出一部分旧数据(batch read),查询LSM-Tree,如果这条数据已经被覆盖或删除,那么就丢弃此数据;否则从head指针处写入此条数据。
为了保证在GC过程中的crash不产生数据的丢失,GC的流程为:
- 将tail处的KV写入到head处,并调用
fsync()将其持久化 - 同步的将KV的新位置,和head/tail指针的最新位置写入LSM-Tree
由于我们使用了LSM-Tree的WAL,可以保证所有在LSM-Tree里的数据都是可用的。
崩溃一致性(Crash Consistency)
在垃圾回收一节中,我们其实已经遇到了一致性的问题。其根本原因,在于LSM-Tree和vLog是两个不同的模块,在其间保持一致性必然是困难的。
WiscKey使用了现代文件系统(ext4,btrfs和xfs)的一个有趣特性,即对于一个(将要)写入文件的数据流,文件系统会保证这个数据流的一个前缀(或者整个数据流)成功写入文件。
WiscKey的优化
vLog写入Buffer
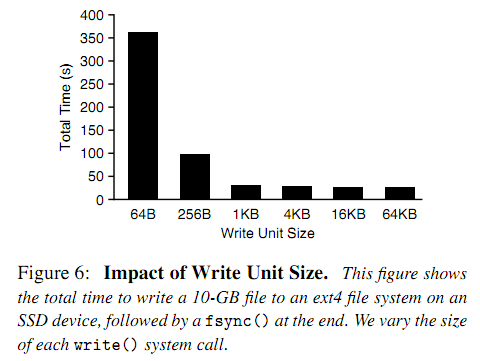
众所周知,磁盘的同步写入必然会带来一些overhead。对于小数据来说,这在性能上会产生严重的损耗。
这里的优化类似于将vLog也添加一个memory table,所有写入vLog的数据都先写入这个memory table,然后依次flush到磁盘上。
这样的优势在于将写入batch化,可以减少overhead,提升性能。劣势在于,在系统崩溃时,可能会丢失部分数据。但丢失数据时,仍能抱证上文提到的崩溃一致性。
优化LSM-Tree WAL
LSM-Tree的WAL虽然保证了写入的数据的持久性,但是不可避免的,它也会消耗磁盘的一部分带宽。
关闭WAL,意味着LSM-Tree memtable在进程重启时一定会丢失数据。不过我们可以利用vLog重建LSM-Tree(的memtable部分)。
由于vLog之中已经包括了所有的KV对,所以在WiscKey重启时,我们可以从head指针处扫描vLog的数据,由于崩溃一致性的保证,当指针扫描到已经存在于LSM-Tree的数据时,可以认为LSM-Tree已经重建成功。
文件系统的优化
WiscKey使用posix_fadvice()向OS层预声明接下来vLog的操作类型以适应不同场景的磁盘访问模式。使用fallocate(),通过”hole-punching”功能进行GC,以减少数据的移动。
WiscKey的性能
论文的最后给出了一系列数字。由于WiscKey的读写放大很小,所以在value size比较大的场景下(>= 1KB),性能远优于传统LSM-Tree。同时,磁盘空间的使用也更友好。
这里有一个疑问,论文里做microbenchmark的时候,对于LevelDB和RocksDB,是不是还开着压缩。。。
后记
WiscKey应该是“LSM-Tree + KV分离”思路的比较早期的论文,其中仍有很多不明确的细节。但是整体思路是可行的。
PingCAP的Titan是一个基于WiscKey思想的RocksDB KV分离存储引擎。后续可以参考其实现再了解更多的实现思路与细节。
Comments
comments powered by Disqus