背景
之前一直在用七牛云的存储做图床(简称白嫖)。但是免费的午餐必然不会长久,七牛要求所有bucket都要绑定备案过的域名,否则就停掉你的bucket的外链。这事我也不吐槽,毕竟是白嫖,也不能要求啥。
但是最智障的是,你外链停了没关系,但是我在后台portal查看文件,上面的图还是显示不了,点下载也没有反应,只显示“ [5402] 获取 bucket 域名失败”。说好不嫖了,你却又不让我走了,都没办法数据迁移的。
因为博客里的图全都存在了七牛的图床上,这么一波搞下来就非常伤。于是我积极展开自救行动。
大侦探毛利小五郎
我:你看我们天天查问题,像不像柯南在查案子?
同事:我觉得我们更像毛利小五郎。
大胆猜测七牛的portal也是使用了外链的URL,如果不绑域名的话,是没有文件的URL的。但是我手里又没有备案后的域名。事情就陷入了僵局。
七牛提供了小工具(qrsctl)让我们管理文件,我觉得这可能是个突破点,万一小工具可以把数据下载下来呢?结果也是不行,这就非常GG了。
此时,我又发现小工具有拷贝数据的功能,可以把跨bucket拷贝数据,但是我的所有的bucket都没有绑域名。也并不能解决问题。
我突然又想到,七牛云其实并没有完全禁止外链。对于一个全新的bucket,七牛会免费提供30天的测试域名,所以新的bucket是可以进行文件下载的。
这样问题就解决了,我新建一个bucket,挂上测试域名,然后把文件都下载下来。这样数据就保住了。
一波自信操作
首先我们先从portal上获取ak和sk。
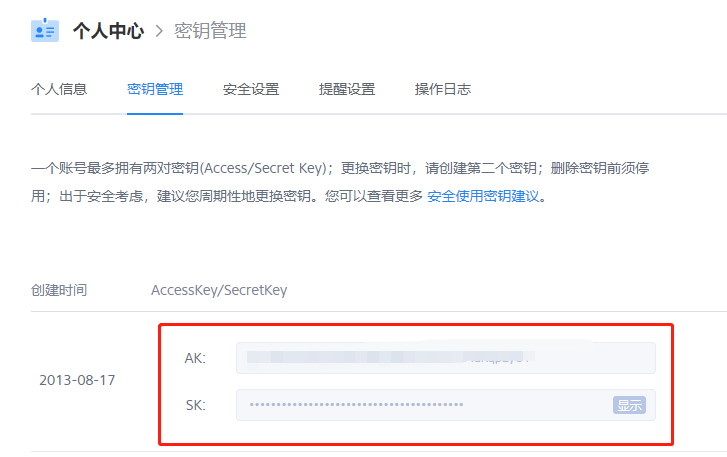
然后使用qrsctl,登录,并获取bucket下面的所有文件。
./qshell_linux_x64 account {ak} {sk} [email protected]
./qshell_linux_x64 listbucket { bucket_name } | awk -F"\t" '{print $1}' > files.txt
接下来把文件拷贝到新的bucket下面。
./qshell_linux_x64 batchcopy { bucket_name } { new_bucket_name } -i files.txt
此时需要登录portal,获取新的bucket的测试域名。然后填入下载配置文件中。
{
"dest_dir" : "./dest_dir",
"bucket" : "{ new_bucket_name }",
"cdn_domain" : "{ your_test_domain.clouddn.com }",
"prefix" : "",
"suffixes" : ""
}
最后把文件统统下载下来,大功告成。
./qshell_linux_x64 qdownload qdisk_down.conf
附录:使用Github做图床
Github的Blob文件都是存在S3的,墙外性能还是可以的。对于博客这种轻量使用场景已经足够用了,而且重要的是Github不会搞个智障操作强行锁你数据。
第一步我们需要申请一个”Personal access token”.
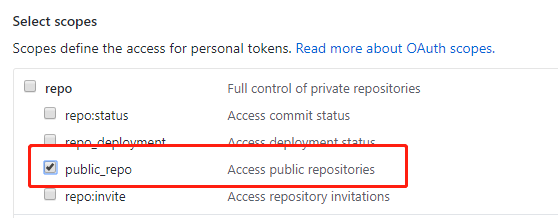
然后允许这个token操纵我们的公开repos。注意,这个token非常重要,请不要泄露!
最后我们可以使用这段代码上传图片(或者其它文件)了:
#coding=utf-8
import sys
import base64
import requests
import datetime
import json
fn = sys.argv[1]
with open(fn, 'rb') as f:
content = base64.b64encode(f.read())
prefix = datetime.datetime.now().strftime("%y-%m-%d")
upload_name = fn.split('/')[-1]
r = requests.put('https://api.github.com/repos/{{ your_id }}/{{ your_repo }}/contents/{{ path_in_repo }}/' + prefix + "/" + upload_name,
headers = { "Authorization": "token {{ your_token }}" },
data = json.dumps({ 'message': 'upload data', 'content': content, 'branch': 'master' }))
info = r.json()
if 'content' in info:
print info['content']['download_url']
else:
print info
Comments
comments powered by Disqus