-
TL;DR
- Autopilot是微软用来自动化运营大规模网络服务的基础架构
- 其设计核心是Device Manager,一个基于Paxos的强一致性分布式状态机,用来保存整个系统的“实际真相”(ground truth),并且根据整个系统的状态确定下一步的行动
- 其它子模块通过与Device Manager通信,在“最终一致性”模型下获取系统信息并执行命令,确保更新可能不是即时的,但最终会在系统中传播
-
概述:
- 微软运营大规模网络服务,需要可靠的数据中心自动管理
- 为了降低数据中心的运营和资本支出而设计
- 负责自动化软件配置和部署、系统监控,以及执行修复操作来处理软件和硬件的故障
- 微观的策略则交由各个应用程序来确定。例如,确定哪些计算机应运行哪些软件,或者精确地定义和检测需要修复的故障
-
设计原则:
- 基于大规模“商品级计算机系统”的经济性和不可靠性,Autopilot采用容错和简化设计
- 容错设计:非拜占庭式故障模型,解决数据中心的控制环境问题
- “非拜占庭式故障模型”假设系统中的错误不是恶意或欺诈性的。在这种模型中,系统的故障被认为是由于一些常规原因,如硬件故障、软件缺陷或网络问题
- 简化设计:
- 强调简单性和容错性
- 在构建大型的可靠、可维护系统时,常常选择简单设计而非更高效或看似更优雅但更复杂的解决案。
-
系统概览:
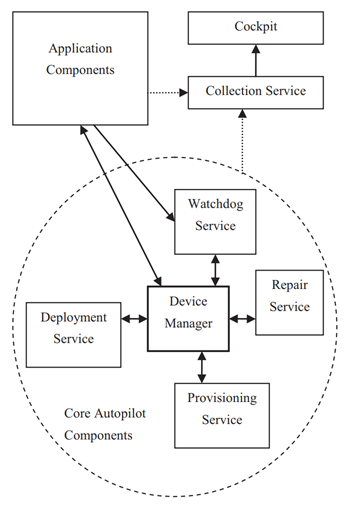
- Autopilot分为多个组件
- 平衡弱一致性和强一致性之间的抉择
- 弱一致性:增强可用性
- 强一致性:简化设计
- Device Manager - 状态和逻辑管理
- 所有关于系统应处于的“实际真相”(ground truth)状态以及更新这一状态的逻辑,都保存在一个称为 Device Manager 的强一致性状态机中,通常分布在5至10台计算机上
- 使用 Paxos 算法实现副本间的一致性,同时通过批处理更新以平衡延迟和吞吐量
- Device Manager与“卫星服务”
- “卫星服务”在发现 Device Manager 状态需要时,惰性地向自身或其客户端的同步信息
- 如果“卫星服务”发现集群中的故障或不一致,它不会尝试纠正,而是将问题报告给 Device Manager
- Autopilot会综合这些信息做出下一步决定
- 当 Device Manager 更新其状态时,会通知“卫星服务”。“卫星服务”也会通过心跳信息尝试拉取最新的状态。简化设计的同时,并且保证最终一致性/正确性。
- Autopilot分为多个组件
-
底层服务:
- 使用稳定的Windows Server操作系统镜像,包含Autopilot配置文件和服务
- 配置服务(Provisioning)包括DHCP和网络引导,不断扫描网络中新接入的计算机
- 通过Device Manager提供的信息来决定需要运行的操作系统及二进制程序
- 应用部署
- 定义不同机器类型,存储不同配置文件和应用二进制文件
- 部署新代码时,以Scale unit为单位更新/回滚各机器类型的配置
-
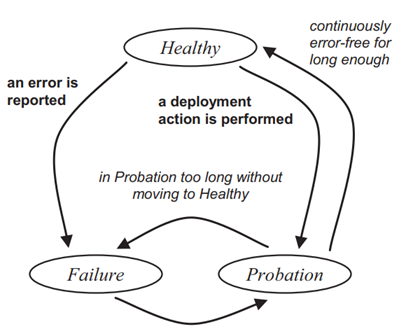
自动修复服务
- 使用最小化的故障检测和恢复模型,以节点或交换机为单位,不处理特定进程的错误
- 只包括Reboot / ReImage / Replace 三种操作
- Autopilot无需对错误归因,也不需要相关的错误处理逻辑
- 用看门狗进行故障报告,检测特定的属性,并上报给Device Manager
- Device Manager作为一个集中式程序,控制机器的自动修复,并且控制同时进行修复机器的数量
- 使用最小化的故障检测和恢复模型,以节点或交换机为单位,不处理特定进程的错误
-
监控服务:
- 记录性能计数器和日志,收集服务形成分布式集合和聚合树
-
案例研究 - IndexServing:
- 介绍Windows Live Search如何与Autopilot交互,保持高可用性
- 对于需要高可用性和低延迟的面向客户服务的应用程序,需要在基础的 Autopilot 组件之上增加定制的容错层
- 使用Load balancer和定制的监控服务来探测失效的或者慢速的节点,并且将结论上报到Autopilot
-
经验与教训:
- 对于关键的配置文件,进行checksum检查是必须的
- 避免人工失误(例如部署因Debug而临时修改的配置)或者其它意外问题
- 网络是不可靠的
- TCP/IP的checksum非常弱,所以需要应用层面的额外检查
- 网络硬件经常翻转数据流中的bit位,导致大量的重试或者未被网络层检测到的数据错误
- 一些节点偶尔会运行的异常慢,但是并不会停止工作。这种问题与“失败停止错误”一样需要被及时检测到
- 节流与负荷削减对于自动化系统非常重要
- 失效检测模块需要有效的区分节点失效与节点过载的区别
- 简单的移除节点可能会导致级联式的失效,进而使整个系统失效
- 对于关键的配置文件,进行checksum检查是必须的
- 论文
本文大(划掉)部分内容由ChatGPT4生成
Comments
comments powered by Disqus